# MySQL教程 - 13 事务
什么是事务?
事务是一组操作的集合,这些操作被当成一个整体进行执行,事务中的操作要么全都执行成功并提交(Commit);要么全部撤销并回滚(Rollback),从而保证数据库的一致性。
举个最常用的例子:
银行转账,张三向李四转账1000元,这里包含三个步骤:
- 张三查询余额是否大于1000
- 张三的余额
-1000 - 李四的余额
+1000
在项目中,业务逻辑代码操作上面的步骤是一步一步调用的,如果遇到代码报错,后面的步骤就无法执行。如果上面的步骤不是一次性执行成功或全部撤销,就会造成银行账户的错误,例如张三的余额减少了,李四的账户却没有增加。
所以就需要事务,保证所有的操作在一个事务内,所有操作要么都是成功的,要么全部撤销。
首先准备一下数据,准备一下银行账户表:
-- 创建银行账户表
CREATE TABLE tb_account (
id INT AUTO_INCREMENT PRIMARY KEY, -- 账户ID,自增主键
account_number VARCHAR(32), -- 账户号码
name VARCHAR(128), -- 姓名
money DECIMAL(10, 2) -- 账号余额
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 插入数据
INSERT INTO tb_account VALUES
(1, '600001', '张三', 2000),
(2, '600002', '李四', 2000);
-- 这个后面用来恢复数据,因为要重试操作
UPDATE tb_account SET money = 2000 WHERE name in ('张三', '李四');
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 13.1 事务操作
正常的操作,有以下三个步骤:
-- 步骤1:查询张三余额
SELECT * FROM tb_account WHERE name = '张三';
-- 步骤2:张三账户-1000
UPDATE tb_account SET money = money - 1000 WHERE name = '张三';
-- 步骤3:李四账户+1000
UPDATE tb_account SET money = money + 1000 WHERE name = '李四';
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
正常执行是没有问题的,但是在执行的中间出错,就会出问题了。
恢复数据后,作为整体执行如下语句:
-- 步骤1:查询张三余额
SELECT * FROM tb_account WHERE name = '张三';
-- 步骤2:张三账户-1000
UPDATE tb_account SET money = money - 1000 WHERE name = '张三';
-- 这个地方让SQL报个错
这个地方报个错;
-- 步骤3:李四账户+1000
UPDATE tb_account SET money = money + 1000 WHERE name = '李四';
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
上面的语句是作为整个脚本一次性执行的,使用执行脚本命令来执行:
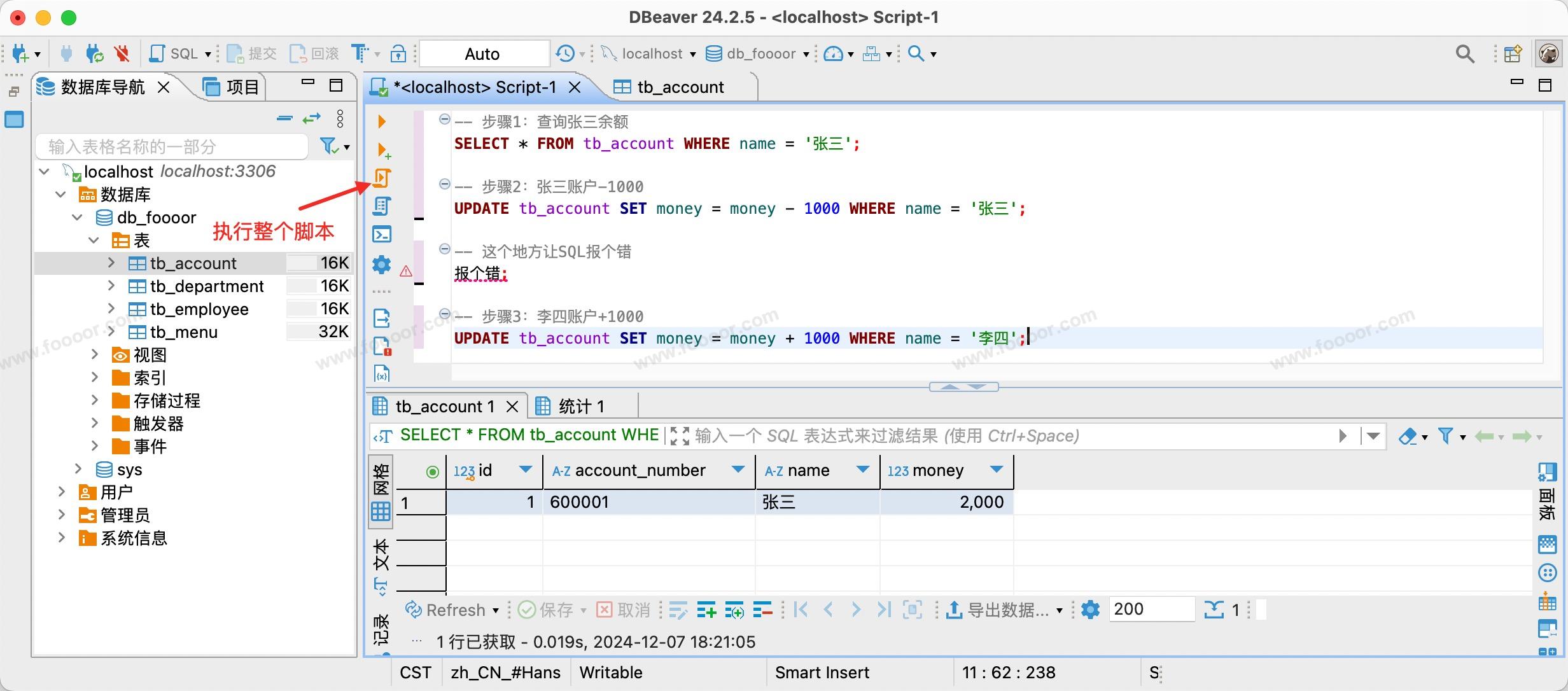
执行的时候,会报错,最终导致账号数据发生不一致:

我的1000不见啦!
MySQL 事务默认处于自动提交模式,每条 SQL 语句执行后会自动提交,所以每条语句在一个事务里面,我们要做的是要将之前的三条语句放到一个事务中。
# 1 设置事务模式
将三条语句放在一个事务中,我们可以先关闭事务自动提交,然后执行完操作后,手动提交事务。
需要使用的事务相关的语句如下:
内容未完......